Autodrive Series 1-kitti dataset search
This post about auto drive
These days I am search on the auto drive things, here is the recording of the rearch process. > 本文由中南大学较为牛逼的研究生金天同学原创,欢迎转载,但是请保留这段版权信息,如果你对文章有任何疑问,欢迎微信联系我:jintianiloveu。牛逼大神一一为你解答!
kitti Dataset Intro
kitti dataset include a lot of data, such as flow and object detection and tracking. This part mainly about object detect. First we work on the data of object tracking. This data have lots of stereo images. Lots of orginaization have benchmark on the data. My work is reimplement the benchmark source code for the dataset.
kitti object detection benchmark
this benchmark implement is a little difficult. First of all, we have Detection data and Ground Truth data. Detection data can be describe as follow:
Car -1 -1 2.010000 670.401855 173.185532 725.845154 198.735275 -1 -1 -1 -1 -1 -1 -1 0.99683654308319091796875000000000
every colomuns means:
#Values Name Description
----------------------------------------------------------------------------
1 frame Frame within the sequence where the object appearers
1 track id Unique tracking id of this object within this sequence
1 type Describes the type of object: 'Car', 'Van', 'Truck',
'Pedestrian', 'Person_sitting', 'Cyclist', 'Tram',
'Misc' or 'DontCare'
1 truncated Float from 0 (non-truncated) to 1 (truncated), where
truncated refers to the object leaving image boundaries.
Truncation 2 indicates an ignored object (in particular
in the beginning or end of a track) introduced by manual
labeling.
1 occluded Integer (0,1,2,3) indicating occlusion state:
0 = fully visible, 1 = partly occluded
2 = largely occluded, 3 = unknown
1 alpha Observation angle of object, ranging [-pi..pi]
4 bbox 2D bounding box of object in the image (0-based index):
contains left, top, right, bottom pixel coordinates
3 dimensions 3D object dimensions: height, width, length (in meters)
3 location 3D object location x,y,z in camera coordinates (in meters)
1 rotation_y Rotation ry around Y-axis in camera coordinates [-pi..pi]
1 score Only for results: Float, indicating confidence in
detection, needed for p/r curves, higher is better.
I have to mark that for occluded means this detected box has been hidden by something. alpha means angle of camera toward the detect object.
Hardest part
The Hardest part is caculate overlap and Accuracy and Recall. In here, I got the overlap by a every simple python script:
def calculate_overlap(box_detect, box_ground_truth, on_which=0):
# 计算overlap,返回重叠率,根据on_which标志位计算是否是相对于union区域还是分别相对于box_a,box_b
# on_which = -1,0,1 分别表示相对于重合面积,相对于检测区域,相对于ground_truth区域
assert len(box_detect) == 4 and len(box_ground_truth) == 4, 'overlap 计算要求box必须有四维数据'
assert on_which != -1 or on_which != 0 or on_which != -1, 'on_which 必须是-1,0,1'
# 计算overlap
# 在计算overlap的时候要注意,一定要判断两个区域是否相交,如果丝毫不想交直接略过不计算
ol_x1 = max(box_detect[0], box_ground_truth[0])
ol_y1 = max(box_detect[1], box_ground_truth[1])
ol_x2 = min(box_detect[2], box_ground_truth[2])
ol_y2 = min(box_detect[3], box_ground_truth[3])
ol_weight = ol_x2 - ol_x1
ol_height = ol_y2 - ol_y1
if ol_weight <= 0 or ol_height <= 0:
return 0
else:
ol_area = ol_weight * ol_height
box_detect_area = abs(box_detect[0] - box_detect[2]) * abs(box_detect[1] - box_detect[3])
box_ground_truth_area = abs(box_ground_truth[0] - box_ground_truth[2]) * abs(
box_ground_truth[1] - box_ground_truth[3])
box_all_union = box_detect_area + box_ground_truth_area - ol_area
if on_which == -1:
return ol_area / box_all_union
elif on_which == 0:
return ol_area / box_detect_area
elif on_which == 1:
return ol_area / box_ground_truth
this is the function of calculate_overlap.It returns the overlap rate of detect box. and then, we have to caculate accuracy and recall: Accuracy this word means how precision of my predict.
accuracy = TP/(TP + FP)
this means, accuacy calculate the percent of your right object in your all right object. Recall
recall = TP/(TP + FN)
this means, recall calculate the percent of your right object in your all object in origin sample.
Concret Example In a pool we have 1400 iPhone, 500 Xiaomi Note2, and 400 Sansumg Galaxy S7 Edge. Now we want grab the iPhone in the pool, we grab a net and we got 300 iPhone, 200 Xiaomi Note2, and 100 Sansumg Galaxy S7 Edge. We can calculate our goal like:
accuacy = 300/(300 + 200 + 100) = 50%
recall = 300/1400 = 3/14 = 21%
so we have the conclusion: Sometimes we just get one iPhone and we have 100% accuracy, but the recall is very low
Above all
Next station You Only Look Once, a new algrithm on the way.
Add 2016-12-16
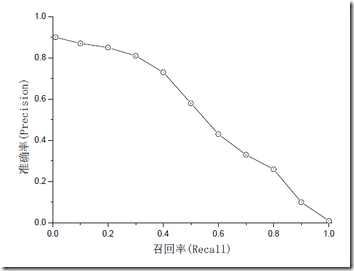
信息检索、分类、识别、翻译等领域两个最基本指标是召回率(Recall Rate)和准确率(Precision Rate),召回率也叫查全率,准确率也叫查准率,概念公式: 召回率(Recall) = 系统检索到的相关文件 / 系统所有相关的文件总数 准确率(Precision) = 系统检索到的相关文件 / 系统所有检索到的文件总数 注意:准确率和召回率是互相影响的,理想情况下肯定是做到两者都高,但是一般情况下准确率高、召回率就低,召回率低、准确率高,当然如果两者都低,那是什么地方出问题了。一般情况,用不同的阀值,统计出一组不同阀值下的精确率和召回率,如下图: 图片
{kind=link}